论文解读《MNN: A UNIVERSAL AND EFFICIENT INFERENCE ENGINE》
本文是对阿里MNN一篇论文的解读,学习重点是了解MNN相较于其他移动端深度学习框架有何优劣,尤其对于移动端人员来说,其中涉及的一些关键概念和优化方案,很值得理解和借鉴。
导读
MNN:https://github.com/alibaba/MNN/blob/master/README_CN.md
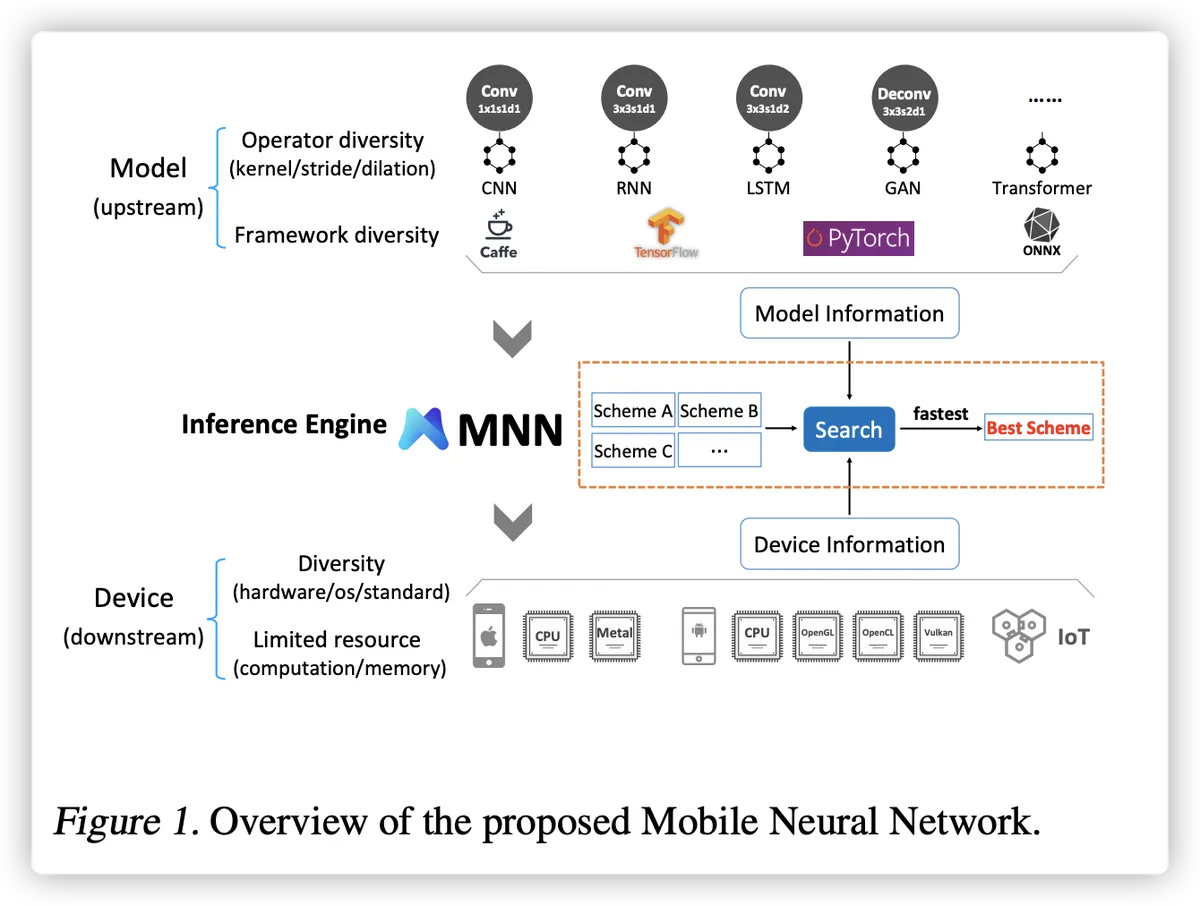
在移动设备上部署深度学习模型最近越来越受到关注。然而,设计 设备上的高效推理引擎面临着模型兼容性、设备多样性和 资源限制。为了应对这些挑战,我们提出了移动神经网络 (MNN),这是一种通用且 为移动应用量身定制的高效推理引擎。在本文中,MNN 的贡献包括:(1) 提出一种称为预推理的机制,可以进行运行时优化; (2)交付彻底 对算子进行内核优化以实现最佳计算性能; (3) 引入后端抽象 启用混合调度并保持引擎轻量级的模块。广泛的基准实验 证明 MNN 与其他流行的轻量级深度学习框架相比表现出色。 MNN是 可在以下网址公开:https://github.com/alibaba/MNN。 (mobile neural network 移动神经网络推理引擎)
端计算背景:
深度学习(机器学习)在移动端部署面临的挑战:
- 多种神经网络模型的兼容性;
- 移动设备的碎片化、多样性(芯片架构、硬件结构);
- 移动设备计算资源限制:CPU、内存
基于此,MNN的解决方案:
- 预推理,运行时半自动搜索(算子聚合、基于机器学习找到计算任务分解的最优解),提高计算效率;
- 卷积算法的优化(高频、头部算子的优化);
- 异构设备的混合调度(资源调度、资源利用最大化);
Introduction
VulKan,OpenGL、OpenCl、GPU、CPU
深度学习已成为人工智能在包括计算机视觉、 用户意图识别(Guo 等,2019)和自动驾驶(LeCun 等,2015)。作为边缘设备(例如,智能手机、 物联网设备、可穿戴设备)现在无处不在,深入 在边缘设备上学习,尤其是移动设备,吸引了 越来越受到关注(Shi et al., 2016)。在手机上进行深度学习有很多优点,例如,低 延迟、隐私保护和个性化服务。至 充分利用设备端深度学习技术,开发了适合移动设备的推理引擎 并广泛用于移动应用程序,例如, TF-Lite(谷歌,2017a)(谷歌,2017a),NCNN(腾讯, 2017)、CoreML(苹果,2017)等。 移动推理引擎面临的主要挑战可能是 分为三个方面:模型兼容、、设备多样性和资源限制。
(1) 模型兼容性。大多数部署在移动设备上的深度学习模型都是从众所周知的 TensorFlow 等深度学习框架(Abadi 等人, 2016)、PyTorch (Paszke et al., 2017)、Caffe (Jia et al., 2014)、 CNTK(Yu 等,2014)、MXNet(Chen 等,2015)。作为 因此,推理引擎是一个基本要求 应具有不同格式和不同运算符的模型兼容性。更重要的是,引擎应该还允许适当的可扩展性以支持新的引擎未来出现。
(2) 设备多样性。几乎所有知名的移动应用程序都广泛用于各种设备,范围包括 从单核CPU的低端设备到Apple Neural等协处理器的高端设备 引擎 (ANE)。为了在各种方面取得出色的表现 设备,移动推理引擎必须带硬件 架构甚至设备供应商(如 ARM Mali GPU 或 Qualcomm Adreno GPU)考虑在内。此外,该引擎也有望很好地解决软件多样性问题,例如不同的操作 系统(Android/iOS/嵌入式操作系统)和不同的解决方案 标准(OpenCL (Khronos, 2009)/OpenGL (Khronos, 1992)/Vulkan (Khronos, 2015) for Android GPU)。
(3)资源限制。尽管硬件发展迅速,但内存和计算能力仍然受限于移动设备并且是数量级的 低于他们的台式机和服务器同行。
综上所述,一个好的移动推理引擎应该具备以下两个特性:
(1) 解决模型兼容性和设备的通用性、多样性;
(2) 在设备上推理模型的效率 出色的性能,使用最少的内存和能源 尽量消费。
为了满足上述特性,我们引入了一个新的移动 名为移动神经网络 (MNN) 的推理引擎。 我们的贡献可以总结如下:
- 我们提出了一种称为预推理的机制,它 通过在线成本评估和最优方案选择,设法执行运行时优化。
- 我们通过利用提供深入的内核优化 改进算法和数据布局以进一步提升 一些广泛使用的操作的性能。
- 我们提出后端抽象模块以启用混合调度并保持引擎本身的轻量级 尽可能。仅将 MNN 集成到应用程序中 将二进制大小增加 400 ∼ 600KB。
应该指出的是,MNN 已被广泛采用 许多移动应用程序。同时,我们开源了 整个项目以丰富社区并希望参与 更多的人让它变得更好。
Related Work
随着目前对设备端深度学习需求的上升, 移动推理解决方案备受关注, 尤其是几家大公司。 CoreML 是 Apple 将机器学习模型集成到 iOS 软件应用程序中的框架,它可以利用 CPU、GPU 和 ANE 等多种硬件。对于安卓智能手机,谷歌也提供了自己的解决方案 用于设备端推理,即 ML-kit 和神经网络 API (NNAPI)(谷歌,2016 年)。然而,这些解决方案的主要缺点在于其普遍性有限。为了 例如,CoreML 需要 iOS 11+ 和 NNAPI 需要 Android 8.1+,排除了许多现有的手机 和嵌入式设备。
2017 年底,谷歌发布了 TensorFlow Lite(TFLite)(谷歌,2017a),一种高效的移动深度学习 框架。 TF-Lite 针对功能较弱的设备进行了优化 例如手机和嵌入式设备。几乎在 与此同时,Facebook 发布了 Caffe2(Paszke 等,2017) 帮助开发人员在移动设备上部署深度学习模型。它们都支持广泛的设备和 许多应用程序已经基于 他们。但是,使用 TF-Lite 或 Caffe2 进行设备端推理 有时可能会违背轻量级的目标。为了 例如,TF-Lite 使用 Accelate、Eigen 和 OpenBLAS 用于浮点加速的库,而 Caffe2 依赖于 Eigen 来加速矩阵运算。整合 具有这些依赖性的移动深度学习框架 将膨胀移动应用程序的二进制大小并带来 在不必要的开销。
为解决问题付出了很多努力 以上。 NCNN(腾讯,2017),MACE(小米,2018), Anakin(百度,2018)是代表。他们 遵循我们称之为手动搜索或非自动搜索的范式。在这个范式中,运算符被优化 通过精心设计的汇编指令逐案处理,不依赖任何外部库。例如, 为步幅 1 的 3 × 3 卷积实现了独特的程序功能;必须实现另一个功能 分别为步长 2 的 3 × 3 卷积。 实现允许移动推理引擎 轻巧高效。然而,逐案优化耗时且难以涵盖所有新的 新兴运营商。
与手动搜索形成鲜明对比的是,还有另一种相反的哲学,我们称之为自动搜索, 由 TVM (DMLC, 2016) 首创。 TVM是一个开放的深渊 学习编译器堆栈,可以将各种深度学习模型以端到端的方式编译成库。不是 它只是解决了冗余依赖问题,但是 还提供图形级和运算符级优化 为模型和后端定制。结果,该 TVM 的性能非常令人鼓舞且可扩展 模型和设备多样性方面。然而,这些 优势是有代价的。 TVM 生成的运行时库是特定于模型的,这意味着如果我们想要 要更新模型(这对于许多 AI 驱动的软件应用程序来说可能非常常见和频繁),我们需要 重新生成代码并发布新版本。这 机制承担成本负担,有时对于移动应用程序是不切实际的。在本文中,我们 有动力开发半自动搜索架构 具有增强的通用性和更好的性能 在移动部署中。
值得一提的是还有一些其他的作品 与设备端深度学习相关,例如,计算 图 DSL(领域特定语言)(Abadi 等人,2016 年; Bastien et al., 2012) 在图中执行优化 水平或算子融合和替换(谷歌,2017b; Wei 等人,2017 年)。这些工作与我们在本文中的贡献是正交的,并且部分被 MNN 引用。
浅谈端上智能之计算优化
- 给定算法模型如何让它跑得快
- 设计牛X的专用硬件
- 结合硬件做深度计算优化
- 通过调度提高硬件利用率
- 给定准确率目标如何让模型尽可能简化
- 如何设计更轻量化的网络结构
- 给定模型的情况下其计算量是否必要(不是的话如何压缩)
其中最大的阻碍之一就是端上的计算资源有限,难以支持多样的、实时的AI相关计算任务。以深度神经网络(DNN)为代表的AI计算任务,本质上是推动了边缘设备计算模式的转变。传统的移动端基本以I/O密集任务为主,偶尔来个计算密集任务可能用户就会觉得发烫,是不是哪里出问题了。而DNN的推理一次就动不动几十亿次运算,而且还是周期性高频率运行,外加系统中可能还有多个DNN同时运行,这传统的玩法根本扛不住。因此,我们的核心问题是算法需求与边缘硬件算力之间的矛盾。而且这个矛盾很可能会长期存在。就像之前的Andy and Bill’s Law,即便算力大幅度提升,市场会出现更多的场景需求,更高的准确率要求把这些增长的算力吃掉。注意算力还与存储、能耗等资源密切相关,因此在移动端性能优化的目标除了耗时外,还包括内存占用及功耗等等。
硬件结构的支持
另外,DNN中的计算中涉及大量参数与中间结果,因此需要很大的memory bandwidth。这多种因素使得DNN的计算很多时候的瓶颈在于访存而不是计算。与CPU不同,GPU拥有数以千计的核心,能同时做并行任务中的操作。这样其整体性能就可以不受单个核心频率的限制。其局限是只适用于规则的可并行计算任务,对于DNN中的矩阵乘加就非常适合,因此,在深度学习的任务中,GPU的吞吐量可以比CPU高出一个数量级。
重点算子的优化
如对于视觉任务中典型的CNN,通常卷积与全连接层会占到总计算量的80%~90%甚至更高。另外像在语音、自然语言理解领域常用的RNN中大量存在LSTM和GRU层,它们本质上也是做矩阵计算。因此很多时候大家做性能优化会focus在矩阵计算上。//针对某种算子的做转化Winograd-based:该方法基于Winograd algorithm。它以更多的加法数量和中间结果乘法数量为代价达到理论上最少的乘法次数。该方法的计算复杂度随着卷积核size平方的速度增长,因此和上面FFT-based方法相反,它主要适用于小的kernel(如3x3)。不过,好在现代主流的神经网络也是以这种小kernel为主,因此被广泛使用。
基于机器学习的半自动搜索,找到计算优化的最优解
机器学习挖掘算法在某个平台架构下怎么拆分当前模型中的计算
算子的聚合,将多个算子简化融合成一个
//IO cache和计算之间的性能差异再次回到访存优化的话题。无论是CPU还是GPU,都存在存储器层次结构(memory hierarchy)的概念。对于这个hierarchy中的每两个层级之间,其速率都可能有数量级的差异。为了让计算尽可能少地访问内存,就需要让程序尽可能cache friendly。做得好和不好有时性能会是成倍的差异。在NN计算优化中,针对访存的优化很多。举两个常见且效果明显的典型例子:Tiling/Blocking:对于两个矩阵相乘,我们知道用原始定义计算的话对cache不友好。如果矩阵比较大的话,尽管一个元素会多次参与计算,但当它下次参与计算时,早被踢出cache了。一个好的办法就是分块。那么问题来了,分块分多大,按哪个轴分,都对性能有很大影响。另问题更加复杂的是这个最优值还是和具体计算任务和硬件平台相关的。一种方法是针对平台做尽可能通用的优化。这就像做爆款,对大部分人来说都不错;另一种方式就是干脆量体裁衣,对给定模型在特定平台通过tuning得到最合适的参数,如AutoTVM通过Halide分离算法实现与硬件上的计算调度,然后通过自动搜索找出最合适的执行参数。经过tuning后其性能很多时候可以超过芯片厂商的推理引擎(毕竟厂商的推理引擎没法给每个模型量身定制)。Operator fusion:这是一种最为常用的graph-level的优化。它将多个算子融合成一个,从而减少运行时间。无论是像Conv-BN-ReLU这样的纵向融合,还是Inception module这种多分支结构的横向融合,其实本质上都没有减少计算量,但现实中往往能给性能带来比较明显的提升。主要原因之一是它避免了中间数据的传输开销。
异构调度-充分压榨多硬件能力
在该问题中,一坨job需要调度到一堆机器上。每个job包含一个或多个必须按序执行的操作。而每个操作必须在指定机器上完成。目标是找到每台机器上的操作序列使得某个性能指标(如makespan)最小。基于JSS问题衍生出非常多的变体和扩展。其中与本节关注问题比较相切的是FJSS(Flexible job shop scheduling)问题。它将操作与机器的绑定关系解除了,即一个操作可以在多台机器上执行。这意味我们还需要确定操作与机器的对应关系,于是调度就分为两个子问题:machine assignment和local scheduling。遗憾的是,无论是对于JSS问题还是它的扩展,亦或是子问题,都是NP-hard的。也就是说,至少在目前的人类文明水平下,无法在多项式时间复杂度下找到最优解。要进行异构调度,还需要有软件框架。这个框架需要有runtime来进行模型解析、优化、调度、执行等任务,还需要能接入各种硬件加速方案以供调度。硬件加速组件需要用HAL进行抽象封装,这样就可以将runtime与HAL加速实现解耦,让第三方加速方案方便地接入。业界的典型例子如Google的Android NN runtime。自Android 8.1以来,厂商可以通过NN HAL接口接入runtime被其调度。另一个例子如Microsoft的ONNXRuntime。它通过ExecutionProvider接口接入多种加速后端。但是,它们目前的分图和调度方案都是基于比较简单的规则,基本原则是哪个快让让哪个跑。这样的贪心策略注定无法得到全局更优的解。虽然通过异构调度我们可以得到一些性能上的好处,但仍有不少的挑战亟待我们解决。如:动态负载:以上的很多方法中,要得到优的调度依赖于精确的cost model。静态条件下的cost model其实还好,可以通过对不同类型的算子进行采样得到样本,然后通过机器学习方法进行建模,可以达到比较低的预测误差。但是,要在考虑动态负载的情况下对广泛的情况建立准确的cost model这就是个比较大的挑战了。而在实际使用中,动态负载是个不得不考虑的问题。比如ASIC是很快,但如果它已经满负载了,再来一个任务的话,与其将它放于ASIC,还不如放在GPU或者CPU上,从而避免一块芯片忙到吐血,其它芯片吃瓜的状态。多任务多优先级:在一个系统中,通常会有多个AI应用同时运行。它们可能有不同的优先级,ADAS可能需要更高优先级,交互相关的优先级可能略低一些。当计算资源冲突时,我们需要进行调度保证前者的延时在可接受范围。这将涉及到资源的优先调度和任务抢占,考虑抢占的话还要考虑抢占的粒度,不同硬件上抢占的实现等。另外,不同任务的主要指标和工作频率可能也不同,如监控中的目标检测一般高频执行,且优先考虑延迟;而车牌识别一般低频执行,优先考虑准确率,对延迟不敏感。所有这些,都是未来值得深挖的方向。
Mobile neural network (MNN)
Overview of MNN
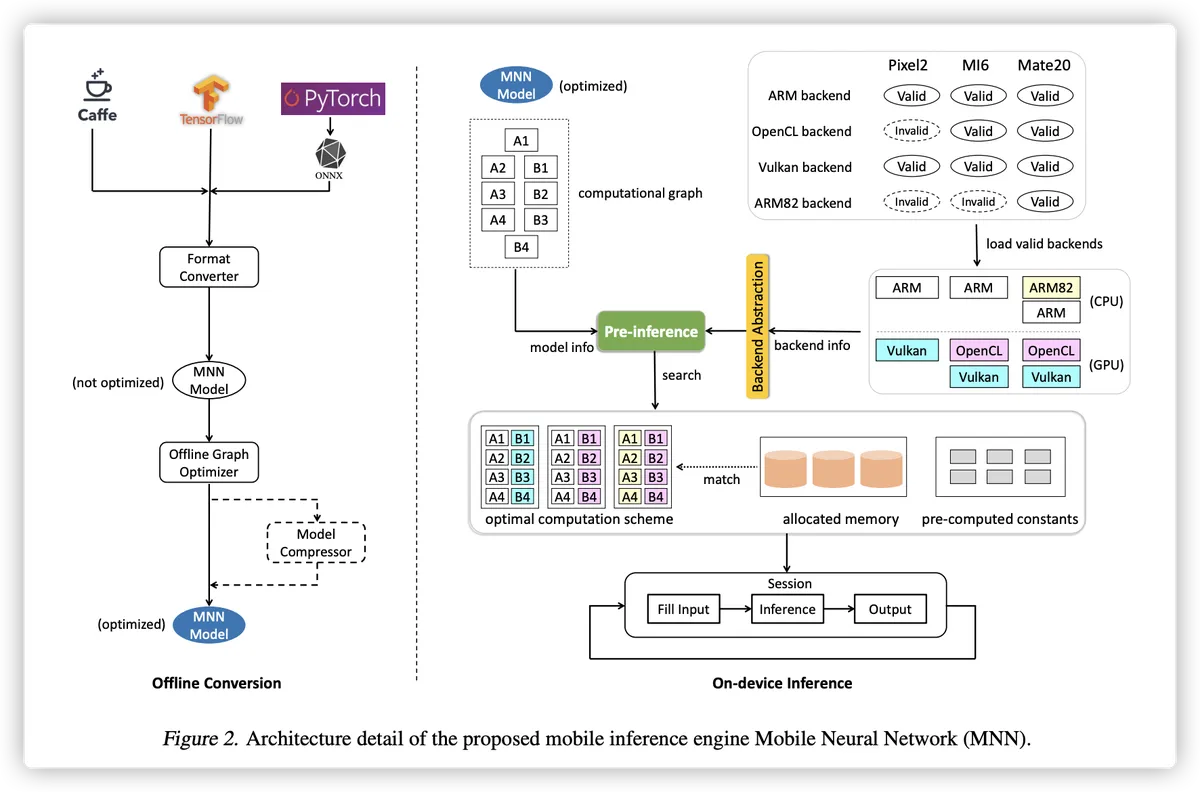
MNN整体分为两部分:
- offline Conversion:离线转换,主要是将一些流行的神经网络模型Caffe、TFLite、Pytorch等转换为MNN模型,进一步会进行一些图的优化比如算子的融合、替换等;
- on-device inference:设备端推理,主要涉及三个模块:预推理、算子优化和后端节点抽象
预推理:主要是将模型计算task与当前后端节点可用资源池,通过机器学习,找到一个最优解,提高计算效率;
算子优化:针对卷积、矩阵相关算法的进一步优化,比如算子的聚合、替换,底层汇编指令;
后端节点抽象:将OpenCL、OpenGL、Vulkan 和 Metal统一成抽象节点,可以支持统一调度。
MNN的基本工作流程由两部分组成, 离线转换和设备端推理。图2总结了MNN的整个架构和本节 简要展示 MNN 如何通过遍历其组件来优化工作流程。 对于离线转换部分,转换器首先取 模型作为来自不同深度学习框架的输入 并将它们转换为我们自己的模型格式 (.mnn)。 同时,执行一些基本的图优化, 例如算子融合(Ashari et al., 2015)、替换、 和模型量化(Rastegari 等人,2016 年)。
对于设备端推理,涉及三个模块:预推理、算子级优化和后端抽象。对于每个算子,预推理模块提供了一个 成本评估机制,将信息(例如,输入大小、内核形状)与后端属性相结合 (例如,内核数量、硬件可用性)从一个动态确定最佳计算解决方案 溶液池。然后算子级优化模块利用先进的算法和技术 像 SIMD(单指令多数据),流水线到 进一步提升业绩。
此外,MNN 支持各种硬件架构,如 后端。由于没有单一的标准适合所有硬件规格,因此 MNN 支持不同的软件解决方案,例如 如 OpenCL、OpenGL、Vulkan 和 Metal。所有后端都是 实现为独立的组件,并提供一套统一的接口,并提供后端抽象模块 隐藏原始细节(例如,异构后端的内存管理)。
使用建议的架构,我们不仅可以实现高 设备端推理的性能,但也使其变得容易 将 MNN 扩展到更多正在进行的后端(例如 TPU、 FPGA 等)。在本节的其余部分,我们将介绍更多 MNN 架构的细节。
Pre-inference
预推理过程中,会提前进行算子的计算策略选择和资源分配。
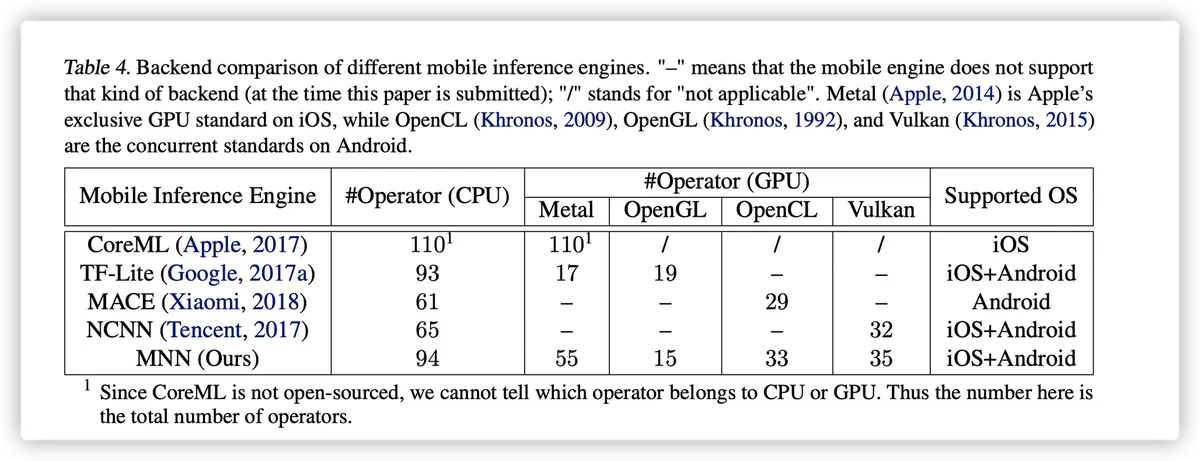
半自动搜索,是在模型结构已知的情况下,在已有的高性能计算模块中,按照一定规则,搜索、组合出最适应该模型的计算方案。它是介于以 TVM 为代表的的全自动搜索(i.e. 自动调优)和以 NCNN 为代表的全手动搜索(i.e. 手工实现每个 case)之间一种新颖的设计思想。它的核心洞察在于,TVM 的自动编译优化,难以匹敌针对硬件特性和算子的手写汇编;同时,模型算子、参数的 case 组合无穷多,无法针对每个 case 进行优化。在最后的「数据论证」部分,我们会用实验数据展示 MNN 相对于全自动搜索(TVM)和全手动搜索(NCNN)的优势。
为了支撑运行时半自动搜索的能力,MNN 提出了一个特殊的处理过程,称为「预推理」。预推理过程中,会提前进行算子的计算策略选择和资源分配。
一般情况下深度学习的应用输入尺寸变动的频率比较小或者可以经过特定的预处理阶段变成相对归一的尺寸。而在输入尺寸确定的情况下,我们可以对模型中每个 Op,计算出它的输出大小以及不同计算策略的消耗以及资源需求量,并以此为依据决定每个 Op 的计算策略,提前进行资源的分配。
计算策略选择
算子的计算策略,包含算法与运行后端的选择。每种算子可以有多种计算策略,不同计算策略适用于不同的输入尺寸,MNN 采用 Cost 计算的方式,去决定计算策略的选取。算法的 Cost 与运行后端的调度 Cost 共同决定了一种计算策略的 Cost。公式如下:
运行后端的调度 Cost,我们通过在大量实际的机器上测试获得。而需要重点关注的是不同算法实现的 Cost。
以卷积为例,假定输入尺寸为
,输出尺寸为
,卷积核大小为
,则有两种计算策略:滑窗/矩阵乘 与 Winograd 算法。
大多数推理框架都会提到「内存复用」,即在网络运行前离线或在线算好每个 feature map 的大小,然后根据数据依赖关系计算一个最大所需内存,申请并把各个 feature map 的指针计算出来。这样做存在一些不易扩展的问题:
- 没有考虑算子内部需要缓存的问题,在不同的计算策略下,算子自身可能需要或不需要缓存(比如卷积用滑窗不需要缓存,用 Winograd 算法需要),这时候算子内部的缓存无法复用或预先分配,会增加内存占用或者影响性能。
- Feature map 对于异构设备而言(主要是 GPU),所需要的资源往往不仅是一块连续内存,因此异构端无法用同一套内存复用机制,往往需要另外写。
- 网络中有可能需要做多路并行,比如 CPU、GPU 各一路,这样之前按整个网络算出来的内存地址就无效了。
MNN 采用一种灵活而简单的策略,解决了资源预分配与复用的问题:
1.计算一遍数据依赖,为每个 Tensor 计算引用计数
2.针对每个算子,把资源管理与计算的代码分开,其中资源管理的代码包括:
(1)计算输出大小
(2)依据输出大小申请 Tensor 资源
(3)算子做 resize 准备:计算策略选择-申请并回收缓存
(4)回收引用计数清零后的输入 Tensor 的资源,回收之后可供下次分配使用
3.在预推理过程中,仅执行资源管理的代码。在推理过程中,仅执行计算的代码。
对于 CPU 而言,资源管理就是内存的申请与释放,资源预分配分别在 MI6 和 P10 上降低了 6.5% 和 7.6% 的推理延时。而在使用 Vulkan 时,资源管理包括显存的申请与释放、Pipeline 资源的创建、Command Buffer 的创建等,这时资源预分配的收益十分可观,分别在 MI6 和 P10 上降低了 75.2 % 和 49.5 % 的推理延时。
Kernel Optimization
算法本身的优化:Winograd 卷积算法的任务分块、大矩阵乘法优化
内核是一个操作符的详细实现,它的 优化可以指定为两种方式,即算法和调度(Jiang et al., 2018)。换句话说, 我们需要选择最低的最优算法 算术复杂度并充分利用可用的 硬件资源以实现最快的执行。
Winograd 算法是由 Shmuel Winograd (Winograd, 1980) 和 已被用于加速 DNN 中的卷积(Lavin & 格雷,2016 年)。 给定大小为 [iw, ih, ic] 的输入特征图,其输出 特征图[ow, oh, oc],Winograd卷积可以表示为
其中 G、B、A 是核 W 的变换矩阵 (空间大小 [k, k]), 输入 X (空间大小 [n+k −1, n+k − 1]) 和输出 Y(空间大小 [n, n])。这些 三个矩阵只取决于 W 和 X 的形状。 我们基于提出的优化 Winograd 卷积 Winograd 生成器采用流行的并行计算技术,如流水线和 SIMD。
(1)块划分和流水线。在 Winograd 卷积 (Lavin & Gray, 2016) 中,X 是一个小瓦片而不是 整个输入特征图,因此给我们留下了第一个问题: 块划分,即如何确定n。 为了解决这个问题,我们从输出的角度来划分块。对于大小为 [ow, oh, oc] 的输出,设 T 为并行计算的乘数(即,我们计算 T 输出 每次块)。那么应该有
其中 nˆ 是在预推理阶段决定的上述最佳输出瓦片大小(等式 2)。 当块一起计算时,我们必须尽力 避免管道停顿以隐藏延迟。套路众所周知 避免管道中的数据依赖 (Kennedy & Allen, 2001)。这是通过仔细的组装说明来实现的 MNN中的重排
(2)Hadamard乘积优化。哈达玛产品 是 Winograd 卷积中必不可少的步骤(参见公式 6)。但是,它有一个问题是内存访问需要 时间长了,拖累了整个加速度。 从式 6 可以看出,求和加 Hadamard 积可以转化为点积。将许多点积组合在一起为我们提供了矩阵 乘法,这是并行度的一个很好的指标 并分摊内存访问开销。本着这种精神, 我们建议将 Hadamard 乘积转换为矩阵 基于数据布局重新排序的乘法构建。这 随之而来的新数据布局称为 NC4HW4(DMLC, 2016;苹果,2014 年)。简而言之,NC4HW4是一种将V(本文中V=4)数据拆分出来的数据布局重新排序方法 元素作为一个单位,为张量创造一个新的维度。 V 元素在内存中连续放置,以便 利用 CPU 中的向量寄存器计算 V 数据 单个指令(即 SIMD)。重新排序后, Winograd 卷积如图 4 所示。
(3) Winograd 生成器。大多数现有的使用 Winograd 的推理框架(谷歌,2017a;腾讯,2017;小米,2018)硬编码 A、B、G 矩阵,用于公共 源代码中的内核和输入大小(谷歌;小米),面对新的可扩展性相对较差 案件。相比之下,MNN 通过 一个提议的 Winograd 生成器,允许 Winograd任何内核和输入大小的卷积。我们采用 以下公式生成A,B矩阵,
Large matrix multiplication optimization
如前所述(第 3.2 节),卷积运算 内核大小为 1 的情况在 MNN 中被转换为大矩阵乘法,由此而来的是 Strassen 算法(Strassen, 1969)加速。据我们所知,MNN 是第一个采用 Strassen 算法来加速大型矩阵乘法的移动推理引擎。 Strassen 是一种快速算法,它用廉价的加法来交换昂贵的乘法,其加速效果是 递归应用时最大化(Blahut,2010)。 在实践中,我们需要决定何时应该进行递归 停止。条件是在现代处理器上,乘法的成本几乎与加法相同,因此我们可以 只需通过他们的数字比较他们的成本。在 MNN 中,对于 大小为 [n, k] × [k, m] ⇒ [n, m] 的矩阵乘法, 直接乘法的次数是 mnk,而它只 需要 7 · 米 2 n 2 克 使用 Strassen 进行 2 次乘法。额外的 使用 Strassen 的成本是 4 次矩阵加法 [ 米 2 , 克 2 ], 大小为 [ 的 4 个矩阵相加 n 2 , 克 2 ],以及 7 个矩阵加法 尺寸 [ 米 2 , n 2 ]。因此,递归仅在 收益大于成本,公式为
一旦这个不等式不成立,施特拉森的递归 应该停止。
表 3 展示了 Strassen 的优势比较 具有不同矩阵大小的直接矩阵乘法。 我们可以看到 Strassen 方法优于直接 一个 7.5% ~ 13.5% 的改进。
Backend Abstraction
后端节点抽象:
xPU、图形操作库
引入后端抽象模块,使所有 硬件平台(例如 GPU、CPU、TPU)和软件解决方案(例如 OpenCL、OpenGL、Vulkan)封装到 统一的后端类。通过Backend类,进行资源管理、内存分配、调度 与具体的运算符实现解开。 Backend 类由几个抽象函数组成,
//一个抽象的硬件设备节点:https://www.bookstack.cn/read/MNN-zh/doc-AddBackend_CN.md

引入后端抽象模块,使所有 硬件平台(例如 GPU、CPU、TPU)和软件解决方案(例如 OpenCL、OpenGL、Vulkan)封装到 统一的后端类。通过Backend类,进行资源管理、内存分配、调度 与具体的运算符实现解开。 Backend 类由几个抽象函数组成, 如图5所示。至于内存管理, onAcquireBuffer 负责分配新的 用于张量的内存和用于释放的 onReleaseBuffer 他们。对于算子实现,设计了onCreate 为每个操作符创建执行实例。 这个特定模块的优点:
(1) 降低复杂性。大量的运营商和 无数的设备使操作员优化成为一项重要的任务。主要挑战在于异构后端通常有不同的方式来管理资源,例如,分配/释放内存和调度 数据。处理这些问题会使实现容易出错和繁琐。统一后端类 管理GPU着色器等资源加载,根据算子的声明完成内存的优化分配。使用后端抽象,MNN 设法将任务分成两个独立的部分。这 “前端操作员”开发人员可以专注于高效 快速操作符执行和所有不相关的实现 后端详细信息被隐藏。 “后端”开发人员可以 致力于开发不同的后端规范和 提供更方便的 API。这种任务分离是 在实践中相当有意义,因为降低了贡献 障碍在开源项目中受到高度赞赏。
(2) 启用混合调度。异构计算 主要涉及后端选择和不同后端之间的数据传输。创建推理时 MNN 中的会话,可以配置目标后端。如果 有多个后端可用,MNN 可以决定 根据上述后端评估(第 3.2 节)为运营商选择最佳后端。结果,MNN 支持operator执行的灵活组合 即使在单个推理中也可以使用不同的后端。例如, 卷积可以在 CPU 上运行,下面的 ReLU 激活可以在 GPU 上运行。在后端类的帮助下, 开发人员无需担心调度和 传输,在引擎盖下自动进行。
(3) 更轻量级。每个后端的实现都可以 作为一个独立的组件工作,同时保持 MNN 中的统一接口。每当一些后端 在某些设备上不可用,相应的具体 实施可以很容易地从整体剥离 框架。例如,Android 平台不支持 Metal(Apple,2014),因此我们可以拿走 无需接触特定操作员的金属模块 实现。通过运算符和 后端,MNN 可以具有竞争力的轻量级。这是来自 至关重要,因为移动应用程序对二进制大小有严格的限制。
通过这些统一的后端接口,尽我们所能 知识,MNN 是推理引擎,支持 最全面的后端(见表 4)。此外,它是 可扩展性足以让用户集成新的后端,例如 NPU、FPGA等
Method Summary
与其他一些典型的设计范例相比 如图 6 所示,我们说明了 MNN 背后的设计理念,并强调了几个 MNN 特定的优势 在这部分。 对于推理引擎,高性能是至关重要的因素 来决定它是否会被开发者采用。 出于这种动机,不同的推理引擎(例如 TFLite、NCNN、TVM)不断努力优化 以不同的方式获得更好的性能。 对于 MNN,我们做了很多改进,以满足高性能的基本要求。采取 考虑到压倒性的运营商多样性,我们是 对逐案优化解决方案不满意。 尽管此解决方案可能相当简单有效,但它 经常遇到一些运营商留下的问题 超出优化成为性能瓶颈 (如第 4.2 节中的示例所示)。相反,MNN 首先发现较小粒度的计算密集单元(即基本矩阵乘法),这是高度 通过快速算法和并行技术进行优化。因此,操作符建立在这个基本单元上 无需特别优化即可自然受益于加速。
此外,可维护性、可扩展性和部署 成本都对长期增长有很大影响 推理引擎。与 TVM 中的自动调谐相比, MNN 能够选择最优的计算方案 更少的时间,并通过提出的预推理机制实现运行时优化。注意,通过将搜索阶段从离线编译转移到在线 预推理,我们也避免了对二进制的限制 验证(例如,iOS 代码签名)。同时,通过提供一套统一的界面来隐藏后台的原始细节, MNN 自然具备模块化的特性。 这个特性不仅使 MNN 变得轻量级,而且 也更方便贡献者扩展 MNN 到更多后端,如运营商数量所示 表 4 中的不同后端支持。
Benchmark experiments
推理引擎:跟CoreML、TF-Lite、NCNN、MACE
硬件结构:CPU、GPU
网络模型:MobileNet、SqueezeNet
在本节中,我们综合评估 MNN 的性能。我们首先解释我们的实验设置, 然后展示在不同硬件上的实验结果 平台和网络,与其他移动推理引擎相比。最后,我们分享一个在线案例来展示 MNN的生产应用。
Experiment Settings
- 推理引擎。我们将性能与 最先进的移动推理引擎,包括 CoreML (Apple, 2017), TF-Lite (Google, 2017a), NCNN(腾讯,2017)和 MACE(小米,2018)。
- 设备。对于 iOS,我们采用 iPhone8 和 iPhoneX (处理器:Apple A11 Bionic),因为它们很受欢迎 在基准1中采用 .对于 Android、MI6(处理器: Snapdragon 835)和Mate20(处理器:麒麟980) 被采用。
- CPU 和 GPU。 (1) 对于 CPU,考虑到现代设备通常有两个线程,评估线程 {2, 4} 或四个处理器和多线程是常见的 加速技术。 CPU 亲和性设置为使用所有 可用内核符合 NCNN 基准(腾讯,2017 年)。 (2) 对于 GPU,我们评估 iPhone 上的 Metal Performance Shaders。在安卓设备上, 三个标准后端(即 OpenCL、OpenGL 和 Vulkan) 被评估,因为 MNN 支持它们 全部(见表 4)。
- 网络。 MobileNet-v1(霍华德等人,2017), SqueezeNet-v1.1 (Iandola et al., 2016) 和 ResNet18 (He et al., 2016) 被选为基准网络 因为它们已广泛用于移动应用程序。
- 运行设置。我们报告了一个的推理时间 224 × 224 RGB 图像(即批量大小为 1),取平均值 通过 10 次运行。在基准测试之前,一个预热推理 进行了与其他作品的公平比较(腾讯,2017;谷歌,2017a)。
Experimental Results
在不同智能手机和网络上的性能。 图 7 显示了 MNN 的性能与 其他四个推理引擎。我们有以下观察。
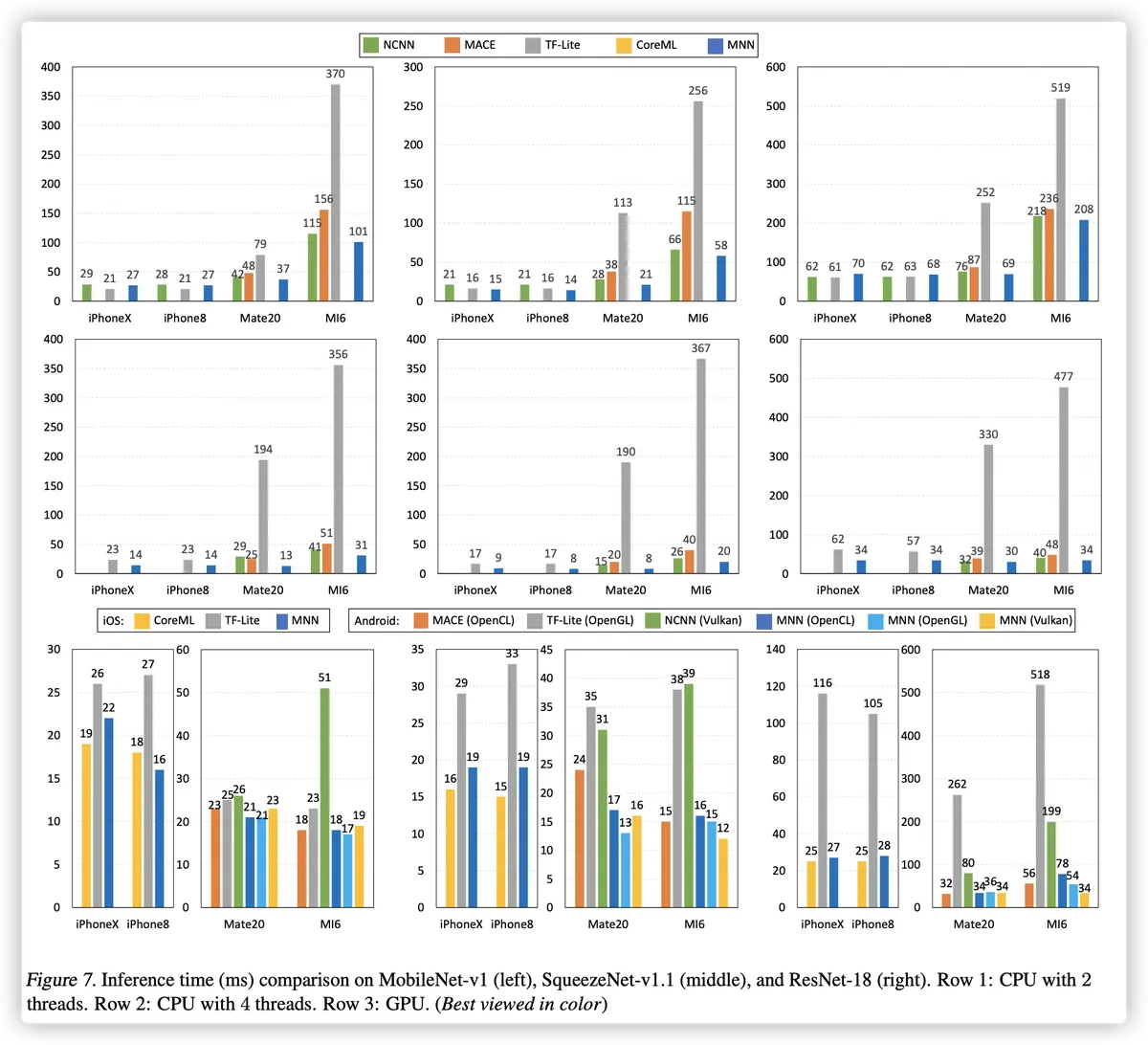
(1) 一般而言,MNN 优于其他推理引擎 在几乎所有设置下大约 20% ∼ 40%,无论 智能手机、后端和网络。
(2) 对于CPU,平均而言,使用MNN的4线程推理是 在 iOS 平台上比其他平台快约 30%,约 在 Android 平台(例如 Mate20)上速度提高 34%。
(3) 对于 iPhone 上的 Metal GPU 后端,MNN 很多 比 TF-Lite 快,比 CoreML 慢一点,但仍然 可比,这是合理的,因为 CoreML 是 Apple 的 专为 iOS 量身定制的 GPU 解决方案,而 MNN 意味着 以支持不同操作系统的后端。为了 Android GPU 后端,其他引擎通常都有自己的 性能盲点。例如,带有 Vulkan 的 NCNN MI6 上的后端不是很快;仍然带有 OpenGL 的 TF-Lite 在 ResNet-18 网络上有很大的改进空间。 相比之下,MNN 在所有不同的硬件平台和网络上都获得了良好的结果。请注意,我们实现了 这种综合性能优势通过 提出的半自动搜索架构,而不是 逐案重优化。
(4) 高端使用MNN的多线程CPU推理 设备(例如 iPhone8 和 iPhoneX)竞争激烈 与使用 GPU 后端相比,这证明了所提出的深度内核的有效性 MNN 的优化。
逐案优化的瓶颈。图 8 显示 Inception-v3 上逐案优化的性能不佳示例(Szegedy 等,2015)。一罐 清楚地看到 NCNN 需要异常更多的推理 时间比别人多。这是因为一些特殊的运算符 在这个网络中(例如,1 × 7 和 7 × 1 卷积)不是 由 NCNN 优化(目前)。因此,他们成为 执行过程中出现瓶颈,严重拖累整体性能。这个具体案例显示了有限的 逐案优化的可扩展性。 MNN 是免费的 这个问题是因为我们的计算解决方案是一个通用的 一种适用于各种卷积情况。
与 TVM 的比较。我们比较性能 各种网络上带有 TVM 的 MNN,如图 9 所示。 尽管 MNN 不应用特定于模型的调整和 优化,MNN 仍有令人鼓舞的表现和 甚至比 TVM 略快。此外,生成 使用自动调整和编译的模型特定代码 TVM 通常会带来一些部署开销。在表 5 2
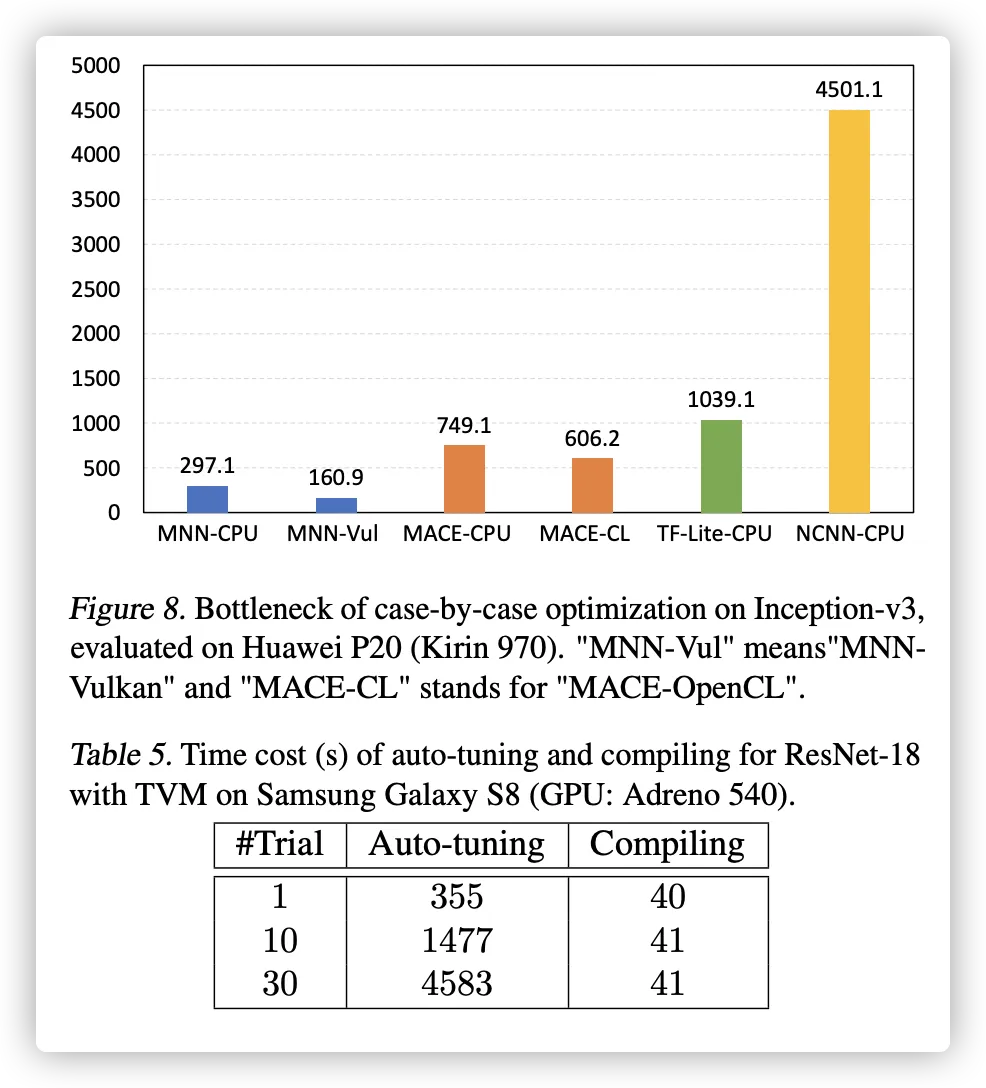
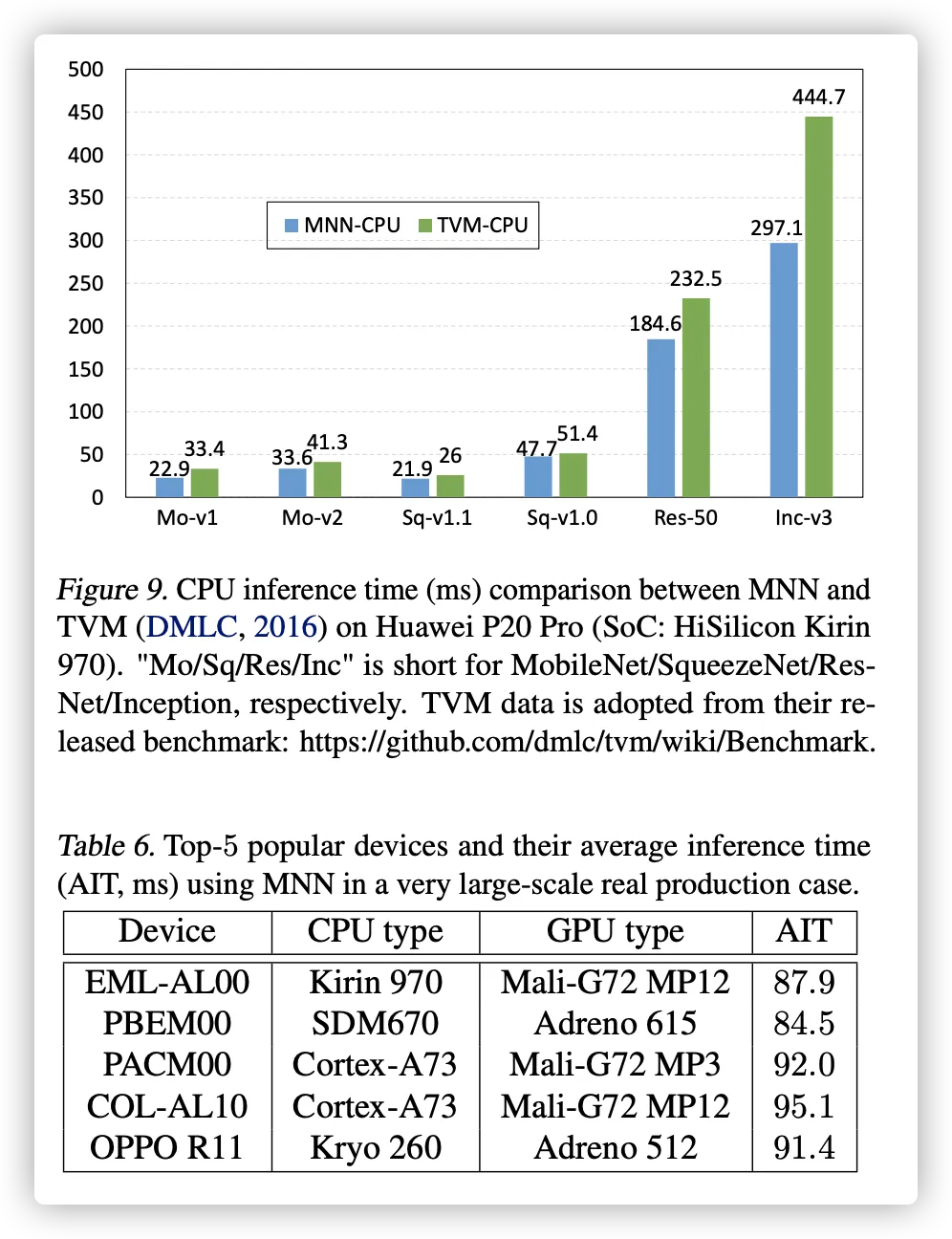
我们展示了自动调整和编译的时间成本 带有 TVM 的 ResNet-18。即使有少量的试验 为了在单个设备上进行调谐,TVM 仍然需要很多时间 生成代码。由于大多数移动应用程序涵盖了许多 不同的设备类型,代码生成的过程会 需要更长的时间并需要更多的资源(例如, 服务器),这对许多开发人员来说是难以负担的。 MNN 没有这些问题,因为所有优化都是 在运行时执行而不会造成性能损失。
Online Case Study
搜索商品是电商平台购物必不可少的环节。但是,由于商品类别的复杂性,传统的方式如今文本搜索无法满足用户的期望。 因此,从图片中搜索商品成为一种 电子商务平台必备的功能。这部分 展示了一个 MNN 在这个场景中的真实应用案例。
在电子商务应用中,采用MNN运行 移动设备上主要对象的深度学习模型 检测和检测结果然后用于商品 搜索。该服务覆盖500多种移动设备,日用户超过1000万。表 6 显示此服务中使用的前 5 名流行设备以及 平均推理时间,其中 MNN 实现稳定和 平滑的搜索体验,平均推理时间 90.2 (ms) 跨越所有不同的设备,无论它们的多样性如何。这显示了 MNN 令人鼓舞的普遍性。
Conclusion and future work
移动推理引擎对深度学习模型至关重要,在移动应用程序上部署,为了应对模型兼容性和设备多样性的挑战,我们引入了移动神经网络(MNN),它提出了 一种新颖的移动引擎设计范式(半自动 搜索)以获得最佳的通用性和效率。 具有彻底内核优化和后端抽象的预推理机制赋予 MNN 良好的通用性和最先进的设备端推理性能。 MNN 仍在快速发展,正在改进 许多方面,例如,
- 在后端评估期间应用自动调整
- 集成模型压缩 工具(例如,剪枝)来动态地精简模型
- 为用户方便提供更多工具
- 提供更多 语言支持,包括 JavaScript 和 Python。