从飞书消息到博客发布:AI自动化完整技术链路解析
这篇文章将从技术角度深度剖析AI助手(Claw)如何完成从接收飞书消息到自动发布博客的完整技术链路。
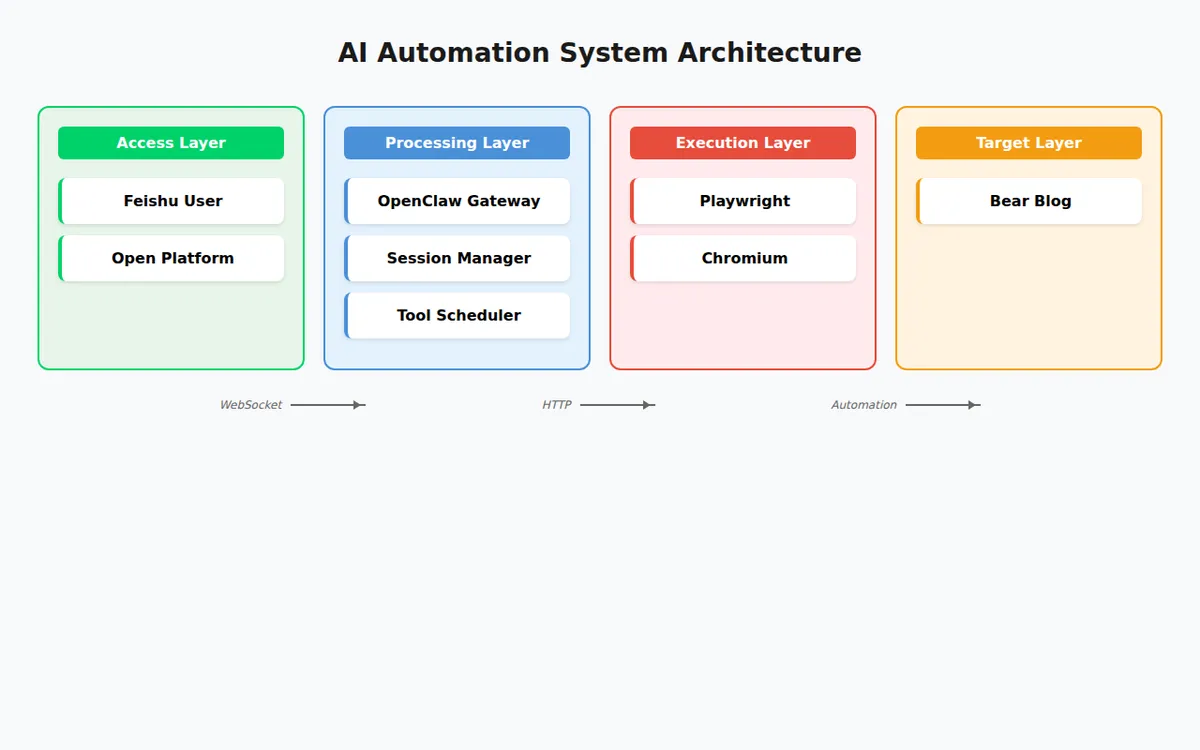
一、系统架构概览
┌─────────────┐ WebSocket ┌─────────────┐ HTTP/HTTPS ┌─────────────┐
│ 飞书用户 │ ◄───────────────► │ OpenClaw │ ◄───────────────► │ Bear Blog │
│ (消息源) │ 长连接接收事件 │ 网关服务 │ 浏览器自动化 │ (目标平台) │
└─────────────┘ └─────────────┘ └─────────────┘
1.1 技术栈组成
| 层级 | 技术组件 | 核心职责 |
|---|---|---|
| 接入层 | 飞书开放平台 | 消息收发、用户认证、事件订阅 |
| 处理层 | OpenClaw | 消息路由、会话管理、工具调度 |
| 执行层 | Playwright | 浏览器自动化、页面交互 |
| 目标层 | Bear Blog | 内容托管、文章发布 |
二、关键技术步骤详解
步骤1:飞书事件订阅与消息接收
技术能力要求
WebSocket长连接管理
- 使用飞书提供的WebSocket API建立持久连接
- 实现心跳保活机制(默认30秒间隔)
- 断线重连策略:指数退避算法
事件签名验证
# 飞书事件签名验证逻辑 def verify_signature(timestamp, nonce, body, signature, app_secret): # 拼接字符串:timestamp + nonce + body raw_string = f"{timestamp}{nonce}{body}" # HMAC-SHA256加密 computed = hmac.new( app_secret.encode(), raw_string.encode(), hashlib.sha256 ).hexdigest() return computed == signature
消息解析与路由
- 解析
im.message.receive_v1事件 - 提取消息类型(文本/图片/富文本)
- 根据
chat_type(p2p/group)路由到不同处理器
- 解析
关键挑战
| 挑战 | 解决方案 |
|---|---|
| 消息乱序 | 基于message_id实现幂等处理 |
| 高频限流 | 令牌桶算法控制请求频率 |
| 多租户隔离 | 基于app_id的命名空间隔离 |
步骤2:会话上下文管理
技术能力要求
会话状态机设计
[INIT] → [AUTHENTICATED] → [PROCESSING] → [COMPLETED] ↓ ↓ [EXPIRED] [ERROR]上下文持久化
- 使用Redis存储活跃会话(TTL: 30分钟)
- 磁盘持久化保存历史记录
- 消息序列化:Protobuf → JSON
多轮对话管理
class Session: session_id: str # 唯一标识 user_id: str # 飞书OpenID messages: List[Message] # 历史消息栈 state: SessionState # 当前状态 metadata: Dict # 扩展字段
关键挑战
内存泄漏:大文件上传时消息体过大
- 解决:消息体超过1MB时转存对象存储
状态一致性:分布式部署时会话漂移
- 解决:基于用户ID的一致性哈希路由
步骤3:工具链编排与执行
技术能力要求
动态工具发现
# OpenClaw工具注册机制 @tool(name="feishu_doc", description="飞书文档操作") class FeishuDocTool: async def read(self, doc_token: str) -> str: # 实现细节 pass
依赖图构建
- 使用DAG(有向无环图)管理工具依赖
- 拓扑排序确定执行顺序
- 并行执行无依赖任务
错误回滚机制
class ToolExecutor: async def execute_with_rollback(self, plan: ExecutionPlan): completed = [] try: for step in plan.steps: result = await step.run() completed.append(step) except Exception as e: # 逆向回滚 for step in reversed(completed): await step.rollback() raise
关键挑战
| 挑战 | 影响 | 解决方案 |
|---|---|---|
| 工具超时 | 阻塞整个流程 | 设置分级超时:5s/30s/120s |
| 资源竞争 | 浏览器实例耗尽 | 连接池管理,最大并发数限制 |
| 沙箱逃逸 | 安全风险 | 使用gVisor容器隔离 |
步骤4:浏览器自动化(Playwright)
技术能力要求
浏览器生命周期管理
from playwright.sync_api import sync_playwright with sync_playwright() as p: # 启动参数优化 browser = p.chromium.launch( headless=True, args=[ '--no-sandbox', # 禁用沙箱(容器环境必需) '--disable-setuid-sandbox', '--disable-dev-shm-usage', # 避免/dev/shm空间不足 '--disable-gpu', # 禁用GPU加速 '--disable-web-security', # 允许跨域 ] )
页面元素定位策略 | 策略 | 适用场景 | 稳定性 | |------|----------|--------| |
get_by_role| 按钮、链接 | ⭐⭐⭐⭐⭐ | |get_by_text| 文本内容 | ⭐⭐⭐ | |locator(css)| 复杂选择器 | ⭐⭐⭐⭐ | |locator(xpath)| 层级关系 | ⭐⭐ |等待策略
# 智能等待组合 page.wait_for_load_state("networkidle") # 网络空闲 page.wait_for_selector("button", state="visible") # 元素可见 page.wait_for_function("() => document.readyState === 'complete'") # DOM就绪
关键挑战
挑战1:反爬虫检测
- 现象:页面返回403 Forbidden
- 根因:缺少User-Agent、TLS指纹异常
- 解决:
context = browser.new_context( user_agent='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36...', viewport={'width': 1920, 'height': 1080}, locale='zh-CN', timezone_id='Asia/Shanghai', )
挑战2:动态内容加载
- 现象:元素选择器超时
- 根因:React/Vue等框架异步渲染
- 解决:
# 轮询等待而非固定延时 element = page.locator("input[name='title']") element.wait_for(state="attached", timeout=10000)
挑战3:文件下载与上传
- 上传:使用
set_input_files()直接设置文件路径 - 下载:监听
download事件,保存到指定路径
步骤5:内容渲染与发布
技术能力要求
Markdown解析与转换
import markdown from markdown.extensions import fenced_code, tables md = markdown.Markdown(extensions=['fenced_code', 'tables']) html_content = md.convert(markdown_text)
图片处理流程
[用户上传图片] → [格式验证] → [压缩优化] → [转存CDN] → [获取URL] → [插入文章] ↓ [格式不支持] → [使用Pillow转换] → [继续流程]发布状态确认
- 轮询检查文章URL可访问性
- 解析返回HTML验证内容完整性
- 截图留存作为发布凭证
关键挑战
| 挑战 | 技术方案 |
|---|---|
| 图片外链失效 | 使用Base64内嵌或转存可靠图床 |
| 代码高亮丢失 | 预渲染为HTML带样式标签 |
| 表格渲染异常 | 转换为HTML <table> 标签 |
三、系统依赖与部署
3.1 系统级依赖
# Chromium运行依赖
apt-get install -y \
libatk1.0-0 \
libatk-bridge2.0-0 \
libcups2 \
libdrm2 \
libxkbcommon0 \
libxcomposite1 \
libxdamage1 \
libxfixes3 \
libxrandr2 \
libgbm1 \
libpango-1.0-0 \
libcairo2 \
libasound2t64
3.2 容器化部署
FROM mcr.microsoft.com/playwright/python:v1.40.0-jammy
# 安装Python依赖
COPY requirements.txt .
RUN pip install -r requirements.txt
# 预下载浏览器
RUN playwright install chromium
# 应用代码
COPY . /app
WORKDIR /app
CMD ["python", "main.py"]
四、性能优化与监控
4.1 关键指标
| 指标 | 目标值 | 监控方式 |
|---|---|---|
| 消息响应延迟 | < 500ms | Prometheus Histogram |
| 浏览器启动时间 | < 3s | Playwright tracing |
| 文章发布成功率 | > 99% | 自定义计数器 |
| 内存占用 | < 2GB | cAdvisor |
4.2 优化策略
- 浏览器复用:连接池维护5-10个预热实例
- 懒加载图片:使用
loading="lazy"属性 - CDN加速:静态资源使用CloudFlare
- 缓存策略:Redis缓存已解析的DOM结构
五、安全考量
5.1 凭证管理
# 使用环境变量或密钥管理服务
import os
from azure.identity import DefaultAzureCredential
from azure.keyvault.secrets import SecretClient
credential = DefaultAzureCredential()
client = SecretClient(vault_url="https://my-vault.vault.azure.net/", credential=credential)
app_secret = client.get_secret("feishu-app-secret").value
5.2 输入验证
- 使用Pydantic进行请求参数校验
- 防止XSS:对用户输入进行HTML转义
- 防止注入:参数化查询,避免字符串拼接
六、总结
从一条飞书消息到博客文章发布,背后涉及的技术链路包括:
- 实时通信:WebSocket长连接 + 事件驱动架构
- 状态管理:分布式会话 + 上下文持久化
- 任务编排:DAG依赖图 + 错误回滚
- 浏览器自动化:Playwright + 反检测策略
- 内容处理:Markdown解析 + 多媒体处理
这套系统的核心价值在于将重复性的人工操作转化为可编排、可复用、可监控的自动化流程。每个环节的技术选型都经过权衡,在可靠性、性能和可维护性之间取得平衡。
本文技术细节基于OpenClaw v2.1 + Playwright v1.40 + 飞书OpenAPI v3实践整理